3Q 2022 | IN-6597
Registered users can unlock up to five pieces of premium content each month.
Deci and the Push toward Accelerated Deep Learning |
NEWS |
The deployment of Artificial Intelligence (AI), mostly in the form of Machine Learning (ML), and more specifically still, by employing DL algorithms, is pretty ubiquitous these days, especially in the cloud, where both training and inference can be carried out, and more and more so at the edge, currently in the form of inference, for the most part. Despite the widespread use of ML, two issues pose particular challenges to a commercially viable AI. One is that deploying ML algorithms do not always result in clear Returns on Investment (ROIs); Intel, for instance, reports that only 20% of vendors employing AI see a ROI. The second issue, which may partly explain the first issue, is that model training requires ever more quantities of both data and energy requirements—bigger models tend to do better, and models also tend to become bigger and bigger—and this is not always viable. Thus, the current importance of accelerators on all aspects of the AI cycle, with one particular, and interesting, example to be found in Deci, an Israeli startup that offers an end-to-end DL acceleration platform for this very purpose.
The Prospect of Improving Accuracy and Efficiency in DL Workloads at the Edge and in the Cloud |
IMPACT |
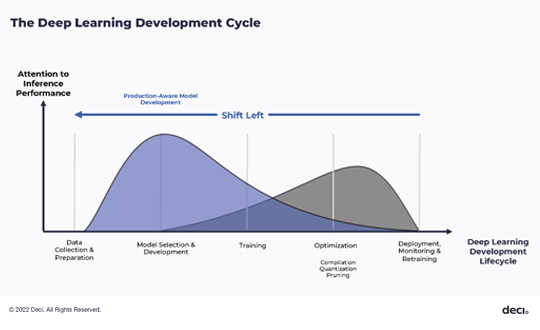
The raison d’être for Deci is a reaction against the standard approach of mostly ignoring the hardware during the training of a ML model, as in the typical case in which a developer runs a model in the Cloud and then applies it to target architecture, such model to be adjusted as needed. Instead, Deci aims to take the hardware architecture into consideration early on in the production phase, according to a “shift left” approach to the classic lifecycle of an AI process, as shown in the graphic below. Within the AI cycle of these stages: 1) model implementation and data collection; 2) data and model selection; 3) model training; 4) model optimization; and 5) deployment/production, Deci’s platform aims to introduce hardware considerations as early as the third step, model training, and more so thereafter.
Based on its own Automated Neural Architecture Construction (AutoNAC) technology, namely, an algorithmic optimization engine that aims to squeeze maximum utilization out of any hardware, and makes use of a Neural Architecture Search (NAS) component, what the platform effectively does is redesign the architecture of a given trained model in order to improve its inference performance for a specific hardware around throughput, latency, and memory, while at the same preserving its baseline accuracy. Deci also offers pre-trained models, which it calls DeciNets, allowing developers to select a pre-trained DeciNet model that maximizes accuracy for the desired task, latency target, and hardware type. Some of the results are very impressive, not the least the 11.8x accelerated inference speedup on Intel Central Processing Units (CPUs) at the MLPerf industry benchmark that Deci has reported. Deci is also involved in edge AI development, ranging from training, compilation, and quantization to deployment, though these are not designed to support TinyML development and deployment, which ABI Research sees as particularly important in the near future. Indeed, ABI Research expects that, by the end of this year, shipments of devices with TinyML chipsets will top the 1 billion figure.
Accelerators Are One Part of the Solution, but Not the Whole Story |
RECOMMENDATIONS |
Deci’s AutoNAC and NAS technologies have been applied dozens of times on various proprietary datasets and tasks, from computer vision to time-series tabular data, mostly on NVIDIA Graphics Processing Units (GPUs) and Intel CPUs, processors that are certainly popular in edge use cases, thus keeping to Deci’s goal of bridging the gap between model complexity and compute power to yield production-ready AI both at the edge and in the cloud. ABI Research certainly believes that these considerations are crucial for proper deployments at the edge and platforms like Deci’s are of paramount importance. In this sense, Deci’s recent announcement that it has raised US$25 million in Series B funding is very good news indeed. However, ABI Research would like to see support for other ML processors, including from silicon startups and, more importantly, from Field Programmable Gate Array (FPGA) vendors. such Other edge AI software companies, such as Edge Impulse and Plumerai, have offered a Deep Learning (DL) optimization solution that is specific for TinyML, while supporting a wide range of edge AI processors. More to the point still, software-based accelerators cannot be the whole story when it comes to solving the interrelated issues of model complexity, compute power, and the underlying hardware. As ABI Research has argued, setups like federated learning, and even few-shot learning, as well as new technologies like neuromorphic computing, are just as important in improving accuracy and efficiency in AI. In the current climate in which environmental considerations are life-changing, running ever bigger models is increasingly hard to justify. Moving inference processes to the edge, and perhaps also training processes in the future, might be the best way to proceed, but for this to happen, a number of factors must all be aligned.