NEWS
NVIDIA & Groq and Intel & SambaNova Make Announcements for Disaggregated Inference
|
Throughout multiple conferences and events so far in 2026, the number of conversations around inference continue to grow. Such conversations cover multiple domains, from inference location and inference engineering, to the compute layer itself. Latency continues to be a major focal point for discussions, especially as models continue to become larger, context windows scale, and agentic workflows begin to be implemented. When it comes to agentic systems specifically, inference latency and throughput are paramount, and demand for higher Tokens per Second (TPS) is causing strains on Graphics Processing Unit (GPU)-only systems. But the industry has been working on multiple software and hardware solutions to resolve this.
During GTC 2026 in San Jose, NVIDIA unveiled its Groq 3 LPX rack as part of its Vera Rubin platform line-up, its first non-GPU-centric accelerator system. This is built around the Language Processing Unit (LPU) Intellectual Property (IP) agreement it signed with Groq in a ~US$20 billion transaction in December 2025. The Groq 3 LPX rack will consist of 32 liquid-cooled 1U compute trays, each housing 8 LP30 chips. In April 2026, SambaNova and Intel announced a heterogeneous hardware solution, leveraging SambaNova’s Reconfigurable Dataflow Units (RDUs) and Intel Xeon 6 Central Processing Units (CPUs), agnostic to the GPU used in the system.
Both systems are targeting general availability from 2H 2026. From a technical perspective, there are slight differences in how inference shall be disaggregated across both systems. The RDU from SambaNova can be responsible for the complete inference process or just the decode phase, while NVIDIA’s approach shall have ATTN processed on its GPU, while decode for Feed-Forward Network (FFN)/Mixture of Experts (MoE) shall occur on the LPU. NVIDIA is enabling this inference orchestration with NVIDIA Dynamo.
IMPACT
The Memory & Token Economics Ramifications
|
One of the main benefits disaggregated inference achieves is that it offloads the decode phase, which is memory bandwidth-intensive, away from the GPU’s High-Bandwidth Memory (HBM) onto the LPU’s or RDU’s Static Random-Access Memory (SRAM). This allows for more Key Value (KV) cache allocation for HBM memory, which is so crucial in multi-step agentic systems. While SRAM technology enables better Time to First Token (TTFT) and TPS, it comes at the expense of total throughput, as well as the chip’s underlying density and cost, which is why the disaggregated inference system makes sense when leveraging the strengths of both memory architectures. It’s important to note that the SambaNova RDU utilizes both HBM and SRAM technology.
The larger impact of the rollout of these disaggregated systems in data centers is that they can enable a fundamental restructuring of how cloud tokenomics works. Not all tokens are created equal. Rather than simply looking at how many tokens are consumed by the user, different tiers can be established based upon the TPS and context window demands of a given workload. For example, coding agents are pushing the need for increasingly larger context windows and TPS as they become more utilized in large, legacy codebases, rather than net-new code, which can be seen through OpenAI’s partnership with Cerebras for GPT-5.3-Codex-Spark, with compute that can run at roughly 1,000 TPS. Table 1 provides an example of a tiered tokenomics setup in the data center, which NVIDIA Chief Executive Officer (CEO) Jensen Huang mentioned during his keynote at GTC.
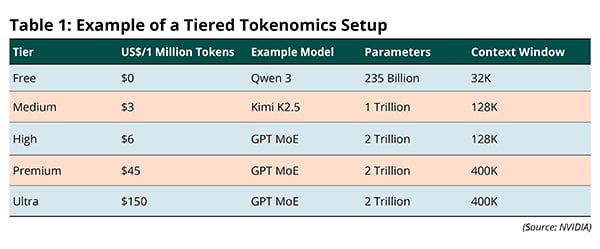
For NVIDIA, the LPX system would be leveraged in the Ultra tier, which would allow for improved TPS without a substantial drop-off in throughput. Based on our own research so far, code generation is a significant driver of active Artificial Intelligence (AI) capacity within data centers, and this is only set to grow over the next decade as it becomes used in legacy codebases and there is greater demand for real-time software development. Monetizing this workload and use case in the Ultra or Premium tiers would greatly improve the economics within the data center and improve the Total Cost of Ownership (TCO) and Return on Investment (ROI) for AI infrastructure.
For all the other tiers, the GPU would still currently be the sole inference compute. It would be in NVIDIA’s and all other GPU providers’ commercial interest for this setup to remain in order to avoid the cannibalization of the GPU business from “Anything” Processing Units (XPUs) and allow them to continue to largely dictate the pricing for different token tiers. That being said, customer demand for better TPS and throughput in lower pricing tiers will continue to create commercial tension. On top of that, the orchestration technology used to disaggregate inference becomes an even more important competitive lever. NVIDIA will likely fully integrate LPUs into its Dynamo platform soon, and other GPU providers will have to do the same with their own solutions in order to better compete in the ~1,000 TPS market.
RECOMMENDATIONS
Orchestration Will Be an Even More Important Differentiator
|
NVIDIA has once again successfully positioned itself at the frontier by introducing a systems architecture for disaggregated inference and must continue to invest in and amplify the messaging around NVIDIA Dynamo. Its strategic importance moving forward is on par with the compute itself and will amplify the NVIDIA ecosystem moat.
AMD’s strategy currently revolves around working with the open-source frameworks such as SGLang and Virtual LLM (vLLM), which enable inference distribution across GPU pools, rather than disaggregating the inference process between XPUs and GPUs. While this allows for more customization for cloud providers, it also reduces the moat for AMD. Furthermore, AMD is directly working with multiple AI inference players such as Clarifai, while others such as FriendliAI are working on optimizing their stack on top of AMD compute, though such players still predominantly run over NVIDIA compute. Having tighter partnerships, or even an acquisition, in this inference engineering landscape to strike a balance between closed- and open-source is key to strengthening this moat. This would not require AMD to move away from its open-source strategy, but will enable it to have more direct control over inference performance on top of its compute as it begins to disaggregate.
For Intel and SambaNova, this partnership announcement is a credible move, but it currently lacks a specific proof point for how another accelerator can be integrated into the disaggregated inference scenario. For example, providing a case study for how workload disaggregation can be performed between an Intel Gaudi GPU and the SambaNova RDU, with the orchestration handled by Intel, would be a strong starting point as Intel continues to strengthen the performance of its GPU products. Intel is already working with Google Cloud on Infrastructure Processing Units (IPUs) alongside CPUs that orchestrate workloads, so they have the capabilities of orchestrating inference.




